Data annotation / classification of vehicle sensor data at scale
Executive Summary
The customer designs and produces premium electric vehicles – no combustion powertrains or hybrids. But they see this as only one aspect of the mobility experiences that will shape life for generations to come. Electrification, connected vehicles, changing ownership models, and autonomous driving are just some of the important trends that are transforming the industry.
As an automotive company that has lots of experience building cars in the old automotive industry fashion and seeks to increase their knowledge about building complex software platforms in the cloud that are needed to fully provide the new mobility experience globally. The solution is part of the platform that will help them to accomplish their goal to become one of the players that will influence the mobility experience for us all.
About NEVS
The automotive industry is the home turf of the company. With a focus on electrical vehicles and mobility solutions it wants to transform the industry globally. It was founded in 2012 with a vision to shape mobility for a sustainable future and the determination to create change for coming generations. This is the north star that guides everything they do.
Customer Challenge
They design and produce premium electric vehicles – no combustion powertrains or hybrids. But this is only one aspect of the mobility experiences that will shape life for generations to come. Electrification, connected vehicles, changing ownership models, and autonomous driving are just some of the important trends that are transforming the industry.
To develop their autonomous capabilities, algorithms that drive the autonomous vehicle should be trained to detect, track, and classify objects and make informed decisions for path planning and safe navigation. Annotation is the process of adding labels of interest (metadata) to an image or a video. Usually, annotated sensor data (including bounding boxes) is used to help AI or Machine Learning models understand and recognize the objects of interest.
In the autonomous drive (AD) development process, high volume of data is acquired from the test fleet through the cameras, ultrasonic sensors, radar, LiDAR, and GPS, which is then ingested from vehicle to the data lake. This ingested data is labeled and processed to build a testing suite for simulation, validation and verification of AD or ADAS models. In order to get autonomous vehicles quickly on public roads, huge training data is required as well as a system that can handle that type of scale.
Vehicle sensor data is output in so-called (ros)bag-format – a bag is a file format in ROS (Robot Operating System) for storing ROS message data. Bags — so named because of their .bag extension — have an important role in ROS, and a variety of tools have been written to allow you to store, process, analyze, and visualize them.
In short, a bag-file is a file that contains a lot of information messages that has been typically recorded by the sensors, you can later use this rosbag-file in “playback” which lets you read the messages in order it was recorded.
Classification of objects being recorded by vehicle sensors, aggregation and the ability to further analyse this data to later develop, for example, testing suites for simulation, validation and verification of AD or ADAS models was the challenge to overcome at NEVS. Primary use-case is to classify camera data from sensors in the vehicles that are outputted in rosbag-format and label recorded objects as well as text. The solution needs to have the ability to scale in order to handle massive amounts of data.
The Solution
In order to begin classification and labeling of the rosbag-files, we need to split the files into images.
This process is kicked off by rosbag-file(s) ingested into S3 with the event notification feature enabled, this triggers a AWS Lambda function that starts Amazon ECS AWS Fargate docker containers which is configured to use a developed ROS docker image with ROS in Amazon ECR. These docker containers split up the rosbag-file into images and are then put into S3.
In order to begin labeling objects and detect texts of the images, we need a service that can analyze the images where we can get an output of the recognized objects and texts but also make sure it works at massive scale. We solve this by using AWS Rekognition label- and text detection in collaboration with AWS Batch. This allows us to process the images asynchronously with an upper threshold of concurrent calls to Rekognition as this otherwise would get throttled for sending too many requests to the service.
The output from Rekognition is then put into Amazon Elasticsearch which provides full-text search, to look up the labels for the images stored in S3. Amazon Elasticsearch also provides an installation of Kibana which is a popular open source visualization tool designed to work with Elasticsearch. Using this graphical user interface we can search for our labels.
The output is also stored in S3 to have the ability to develop testing suites for simulation, validation and verification of AD or ADAS models
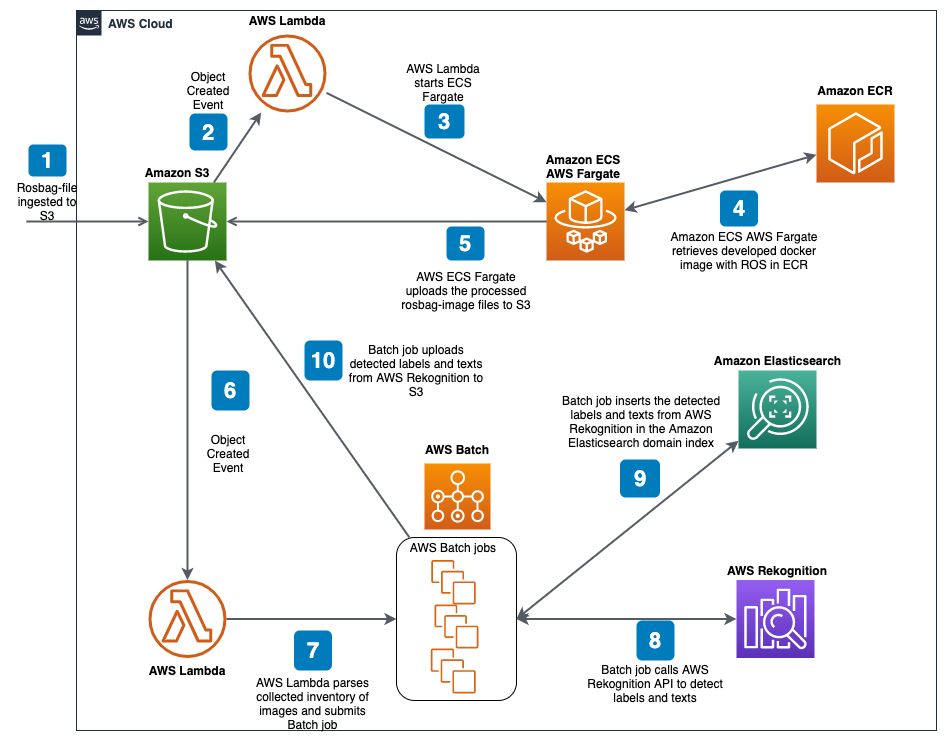
Above is a complete diagram of the solution.
The Benefits
This solution provides NEVS with the ability to annotate the data which their vehicle sensors have recorded.
The solution is elastic, highly available and has the ability to scale in a rapid manner. Without having to collect big datasets and develop our own complex automated recognition software we can get all these out-of-the-box from AWS Rekognition. In collaboration with AWS Batch, Amazon ECS AWS Fargate and AWS Lambda we also have the ability to handle huge volumes of data without scaling issues.
This is a step forward in order to develop testing suites for simulation, validation and verification of AD models, a key component in order to be at the forefront of AD development as it is part of the automated features which comprise the building blocks of semi/fully autonomous driving.
The solution is based on serverless services which has no or little maintenance and provides NEVS with a cost effective but yet scalable solution.
