
How to backup and restore data in dynamodb with Point-in-Time Recovery (PITR)
Having a solid backup strategy is essential to mitigate the risk of losing data in your application.
In this blog post, we’ll take a look at how to enable point-in-time recovery (PITR) for your dynamodb tables, as well as how to restore your data to the table using this backup.
What is point-in-time recovery (PITR) in dynamodb?
Point-in-time recovery is an automatic backup mechanism that continuously backups your dynamodb table data. It allows you to restore your data to any given second during the last 35 days, except for the last 5 minutes in some cases.
PITR offers good protection against accidental deletion of data. If you accidentally delete a table with PITR enabled, AWS will create a permanent on-demand backup for your table, so that you can easily recover the table to the state just before the deletion.
What is the difference between point-in-time recovery and on-demand backups?
You might have noticed that the “Backups” section of the dynamodb console stays empty even after you’ve enabled PITR for your dynamodb table. Those “Backups” are the on-demand backups, and on-demand backups and PITR are different things:
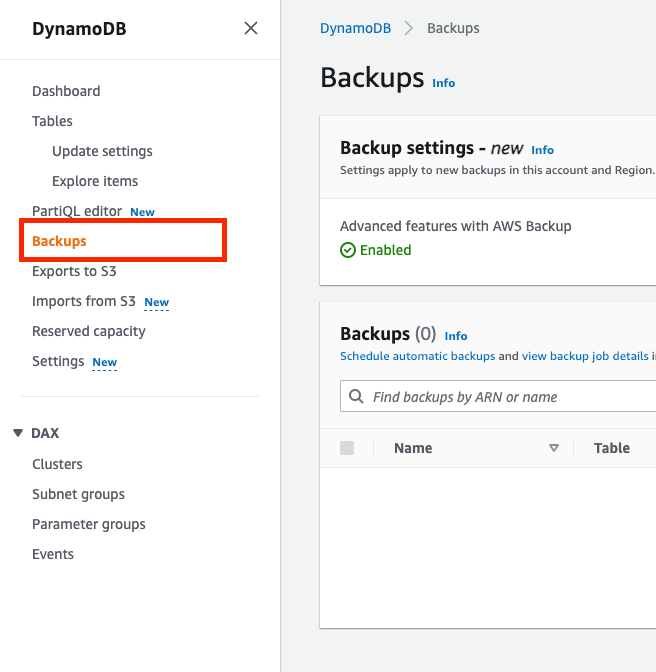
PITR are automatically deleted after 35 days and you can’t modify them. On-demand backups, on the other hand, stay around as long as you don’t actively delete them. You will have to create, maintain and schedule those on-demand backups yourself. You only see the on-demand backups in the “Backups” section above.
How do I enable point-in-time recovery on a dynamodb table?
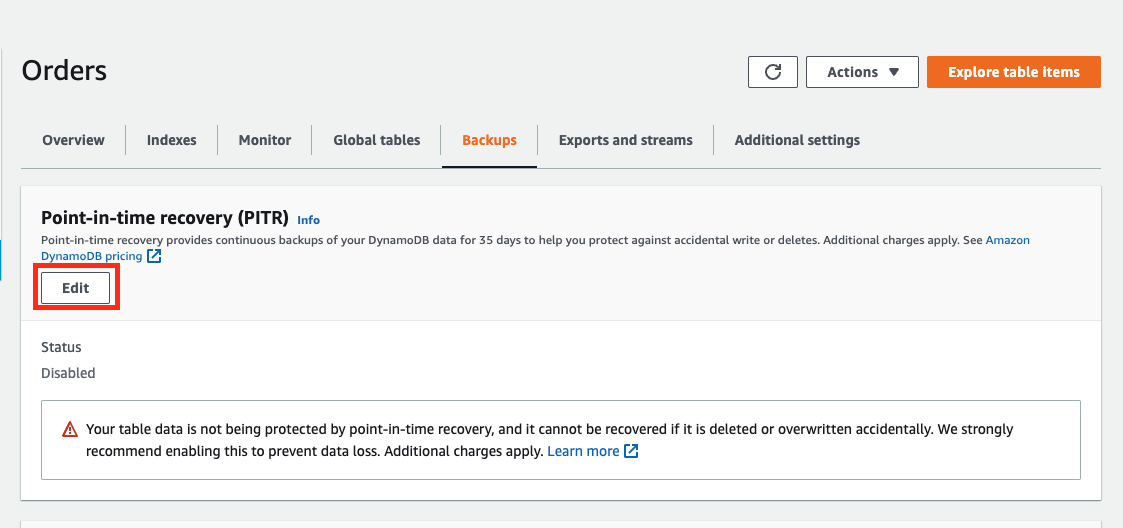
On the console, you can enable Point-in-Time Recovery by clicking on your table name, then on “Backups” and “Edit”:
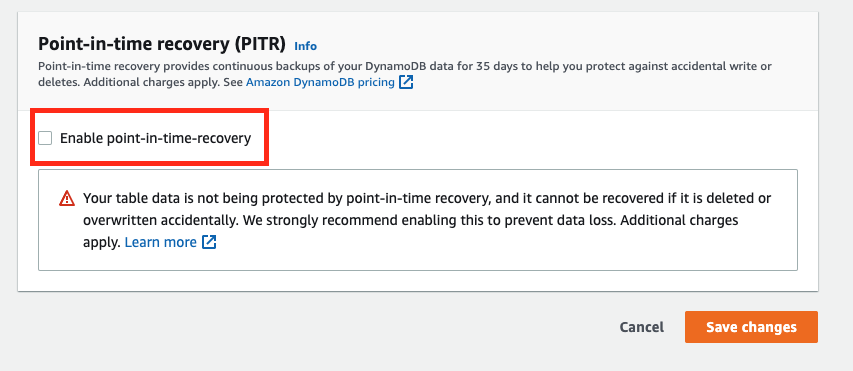
Tick the checkbox on the next page if you want to enable Point-in-time recovery for your table:
Is PITR a full backup?
The PITR contains the entire table data. When restoring from a backup, you can choose if you want to restore the table with or without the local and global secondary indexes. Restoring without the indexes can be both faster and cheaper.
How do I restore data to the original table from a PITR backup?
First imagine the following scenario: for some reason you have lost all the data in your table “Orders”. The table is empty. But luckily, you have enabled point-in-time recovery for this dynamodb table, so you can restore the data.
Restoring data to the original dynamodb table from the PITR backup can be done in two main steps: restoring the data and copying the data back to the original table. Let’s get started with the first one:
Create a restored copy of the dynamodb table
We start out by creating a restored copy of the “Orders” table. To do this we first sign in to the AWS Console, and navigate to “dynamodb”:
-
Click on Tables and choose “Orders” (or choose your own table).
-
Then click on “Backups” and choose “Restore” :
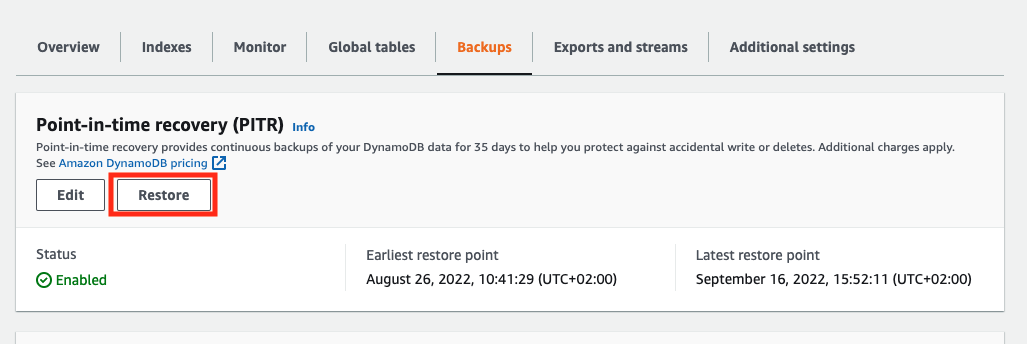
-
Name the backup of the table. In this example we name it “OrdersRecovered”:
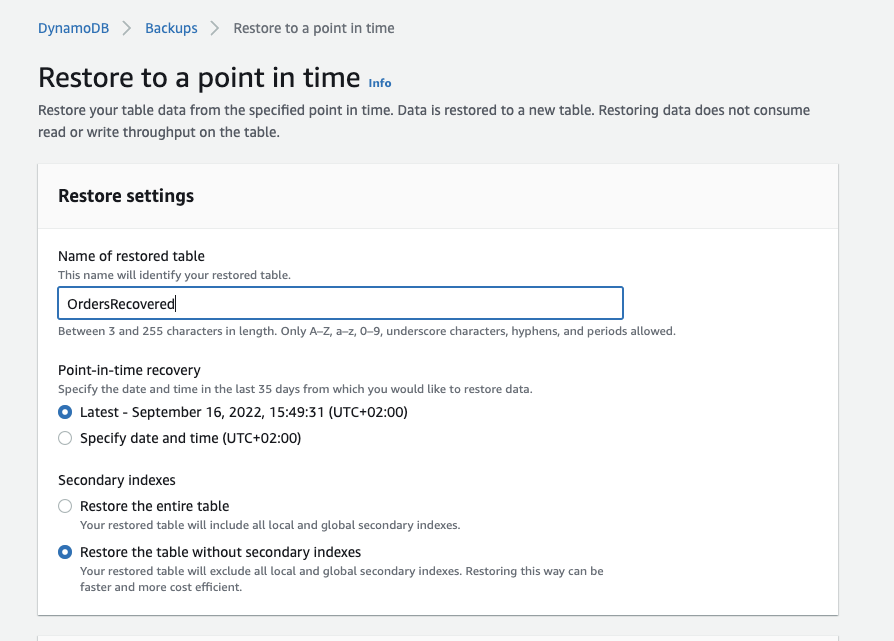
-
On the page above, you also need to pick a date to restore from. It should be a date when the data was still there, so now it helps to know when it was deleted. Otherwise you will have to go with a trial-and-error approach.
-
The next option asks if you want to restore the table with or without the indexes. Since we won’t actually query the restored table in our example, only copy the data, we opt for “Restore the table without secondary indexes”.
-
Unless you have any specific region or encryption requirements. Let the other options stay at their default values and click “Restore”:
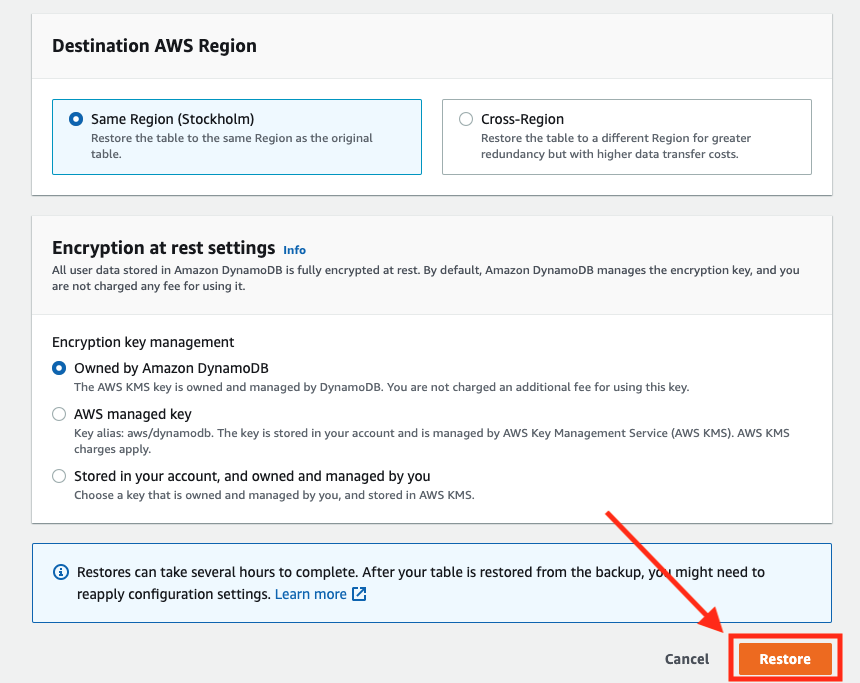
-
Now the “OrdersRecovered” table will appear in the list of Tables. It has the starting “Restoring” until the restore process has been finished. Be prepared to grab a coffee and sit down and wait for some time, this process can take over 20 minutes, even for small tables:

-
When the status of the “OrdersRecovered” table changes to “Active”, the backup has been created and you can start restoring your data from it.
Copy the data from the backup to the original table
Since the PITR backup is always restored to a new table, the original table is still empty and the lost data is still not available there. To get the data back into our original “Orders” table, we need to copy the data from the “OrdersRecovered” to the original table.
There are some alternatives to copying the data, we could just point our application to the new table, so it would use “OrdersRecovered” instead of “Orders”. Alternatively, we could create the backup, make sure it’s the right one, then delete the original table and recreate the backup with the original name.
This last approach is risky because at the moment we delete the original table we loose access to the PITR recovery option for that table, which doesn’t give us any more chances to recover it from a previous state.
To copy the table data you can write a script that performs a dynamodb “scan” operation on the backup version of the table:
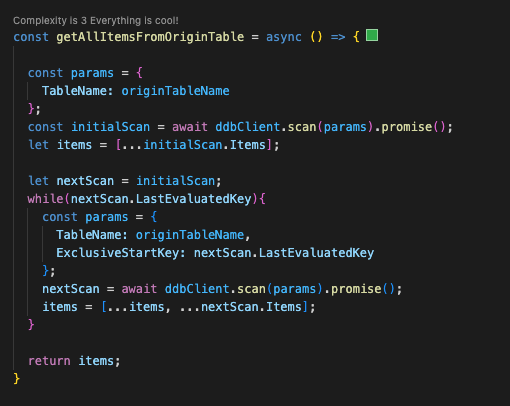
Bear in mind that a “scan” retrieves a maximum of 1 MB of data, and will paginate results exceeding this limit. So always examine the result to see if you find a “LastEvaluatedKey” element. That means that there is more data to be fetched, and you really don’t want to miss that when copying from your backup!
When you’ve retrieved all the records, you can insert them with a dynamodb “put” operation into the new table:
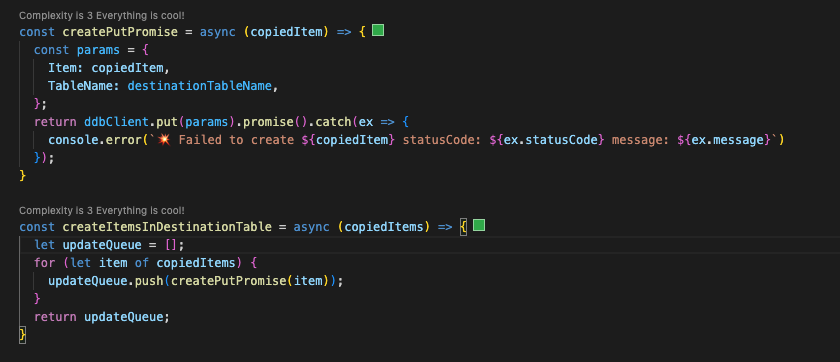
In the script, here is how you can tie the above functions together to get the data from the backup table to the original table:
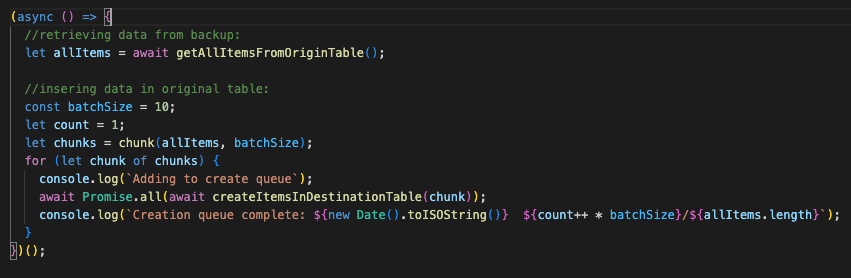
After running this script our table data has been restored.
If you have any questions or comments on this blog post, please feel free to reach out to me:
Elin Fritiofsson



